
Probleme erkennen und lösen: Observability-Praxis im CI/CD-Prozess
Langsame Pipelines, blockierte Reviews, Abbrüche: Um diese Probleme in CI/CD-Pipelines zu lösen, gibt es bewährte Tools und Observability-Praktiken.

(Bild: iX)
- Michael Friedrich
Viele Administratorinnen und Administratoren kennen es: Die CI/CD-Pipelines sind angelaufen und der Prozess testet viele Schritte automatisiert, baut Software, packt Releases und überträgt alles in die Produktion. Eigentlich funktioniert es – wenn da nicht lästige Wartezeiten wären: Reviews blockieren, und Entwicklerinnen und Entwickler können nicht weiterarbeiten. Um den Problemen auf die Spur zu kommen, müssen die Beteiligten die Struktur von CI/CD-Pipelines besser verstehen und mit Observability-Praktiken tief in Prozesse und Workflows hineinschauen, um darauf aufbauend Optimierungsstrategien zu entwickeln. Dieser Artikel dreht sich um Pipeline-Effizienz und Observability-Analysen.

Ineffiziente Pipelines
Auf GitLab findet sich für Testzwecke ein Pipeline-Projekt (siehe Abbildung 1) mit mehreren Stages und Jobs. Das Monorepo simuliert ressourcenintensive Aufgaben (Build aus C++- und Go-Quellen), Frontend-Jobs mit Caching-Anforderungen (Node.js) sowie Test- und Deployment-Jobs auf unterschiedlichen Plattformen (Linux und Cloud Native). Hinzu kommen komplexe Ressourcen-Provisionierungen (Ansible, Terraform etc.), Secrets Management, Sicherheits- und Laufzeit-Observability sowie eine Performance-Überprüfung. Das Projekt stellt die Pipeline-Effizienz vor echte Herausforderungen und dient als Beispiel für wichtige Aspekte der Observability.
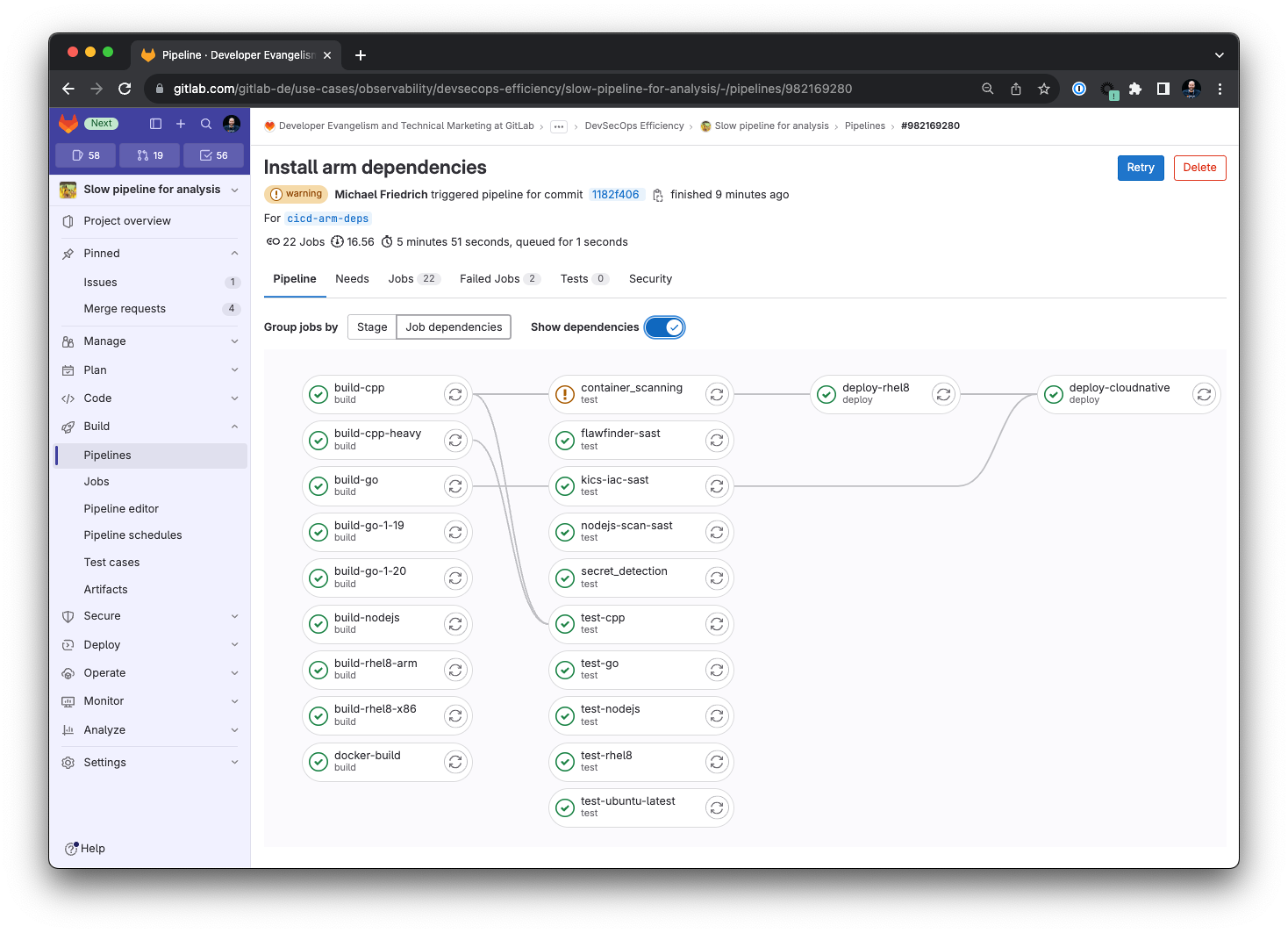
CI/CD-Plattformen verhalten sich im Prinzip ähnlich wie das Beispielprojekt. In einem ersten Schritt bekommen Anwenderinnen und Anwender einen Überblick über die Laufzeit, indem sie sich über fehlgeschlagene und erfolgreiche Jobs ein Bild machen und so erste Muster erkennen. Wenn zum Beispiel die Zahl der fehlgeschlagenen Jobs übermäßig ansteigt, könnte dies mitunter ein Fehler in der CI/CD-Infrastruktur sein, der Benutzer zwingt, diese Jobs immer wieder neu anzustoßen.
Ebenso hilfreich ist es, sich die Laufzeiten der Commits anzuschauen. Zum Beispiel lässt sich die Frage beantworten, welche Code-Änderung dafür sorgt, dass die Pipeline eine Minute länger läuft. Möglicherweise verwendet der Code mehr externe Abhängigkeiten, was die Download-Zeit erhöht, sofern kein Caching konfiguriert ist. Oder die Änderung erfordert längere Kompilierungszeiten, was sich nicht nur negativ auf den aktuellen Merge-Request auswirkt, sondern, falls in den Hauptzweig gemergt, auch auf alle nachfolgenden Entwicklungsarbeiten und Pipelines.
Ein wichtiger Analyseschritt ist, sich einen Überblick über den roten Faden der CI/CD-Pipelines zu verschaffen. Unterschiedliche Plattformen führen Jobs unterschiedlich aus: Sie fassen diese in bestimmten Stages oder Workflows zusammen. Erst wenn die Pipeline einen Workflow mit allen Schritten erfolgreich beendet hat, stößt sie darauffolgende an. Diese Reihenfolge wird zum Problem, wenn Jobs falsch gruppiert sind: Während beispielsweise der ressourcenhungrige C++-Job fünf Minuten läuft, blockiert er die Build-Stage. Dort könnte die darauffolgende Test-Stage schon für alle fertigen Build-Jobs laufen. Als Lösung bieten manche Systeme eine asynchrone Job-Ausführung an, in der Admins Job-Abhängigkeiten definieren.
Im asynchronen Verfahren schreitet die Pipeline unabhängig vom Workflow-Status fort und stößt schnellere Go- oder Node.js-Jobs an und testet sie. Dies ist für Entwicklungsarbeiten von Vorteil, die größere Änderungen vornehmen und nicht alle Builds abwarten sollen. Wenn beispielsweise der Test im Node.js-Build-Job fehlschlägt, während der C++-Build-Job noch kompiliert, können die Entwicklerinnen und Entwickler bereits die Fehlerbehebung angehen. Wenn sie darüber hinaus die fehlerhafte Pipeline abbrechen, sparen sie Ressourcen, da nachfolgende C++-Tests nicht nötig sind. Im GitLab-Beispiel schalten Anwender das asynchrone Verhalten mit dem Attribut needs ein.
Listing 1 zeigt vereinfacht die Pipeline des Beispiel-Projekts mit Build- und Test-Jobs für C++, Go und Node.js mit asynchroner Ausführung. Die Jobs test-go und test-nodejs starten, sobald die entsprechenden Build-Jobs fertig sind, obwohl die gesamte Build-Stage noch arbeitet.
Listing 1: Vereinfachte GitLab-Pipeline mit Abhängigkeiten
# Stage Definition
stages:
- build
- test
- deploy
# Jobs
build-cpp:
stage: build
script:
- ci/build_cpp.sh
build-go:
stage: build
script:
- ci/build_go.sh
build-nodejs:
stage: build
image: ubuntu:22.04
script:
- ci/build_nodejs.sh
artifacts:
paths:
- '*.txt'
test-cpp:
stage: test
script:
- ci/test_cpp.sh
test-go:
stage: test
#Async execution, build stage does not need to finish
needs: [build-go]
script:
- ci/test_go.sh
test-nodejs:
stage: test
# Async execution, build stage does not need to finish
needs: [build-nodejs]
script:
- ci/test_nodejs.sh Tieferer Einblick mit Open-Source-Tools für Metriken
Zur tiefergehenden Analyse bieten sich Observability-Daten in der Form von Metriken und Traces an. Allgemein siehe dazu den Artikel "Observability als Denkweise". Für das Einsammeln von Metriken für Observability-Tools gibt es ausgereifte Open-Source-Projekte wie Prometheus und dessen Exporter-Agenten. Der GitLab CI Pipeline Exporter holt die Laufzeit-Werte von Jobs der GitLab-Rest-API ab. Diese Werte lassen sich historisch in Grafana-Dashboards visualisieren. Der Alert-Manager alarmiert bei zu langen Laufzeiten von Pipelines direkt. Listing 2 liefert ein Beispiel dafür, wie sich der GitLab CI Pipeline Exporter mit Docker Compose starten lässt, um Projekte auf GitLab-SaaS zu überwachen. Das Beispiel erfordert Docker (Docker Desktop, Rancher Desktop, Podman etc.).
Listing 2: Beispiel mit Docker Compose
$ git clone https://github.com/mvisonneau/gitlab-ci-pipelines-exporter
$ cd gitlab-ci-pipeline-exporter/examples/quickstart
$ docker compose up -d
# Grafana ist erreichbar auf http://localhost:3000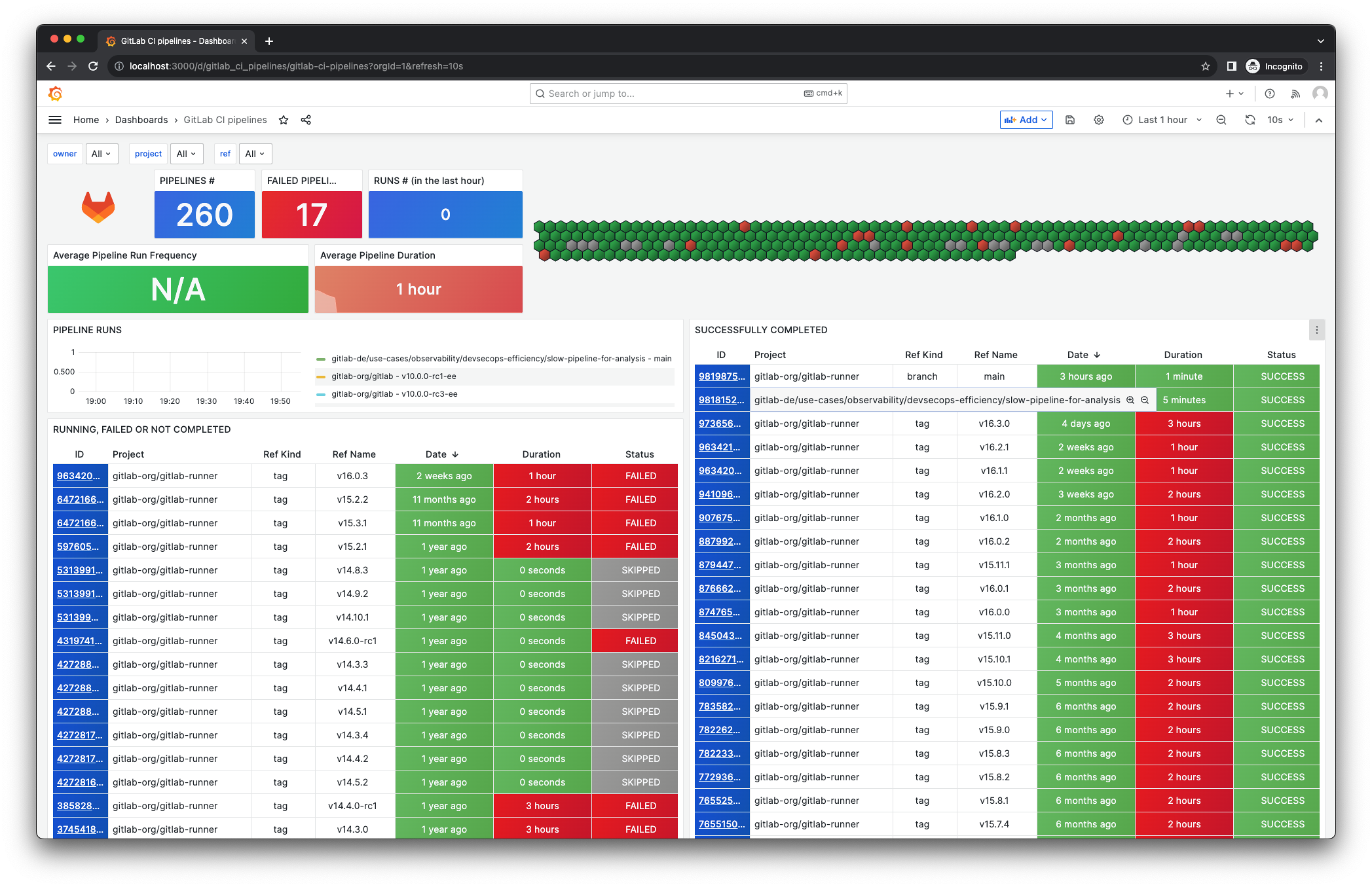
Neben den CI/CD-spezifischen Metriken ist es wichtig, Storage- und Netzwerk-Traffic sowie die Runner- und Executor-Services zu überwachen. Disk-IO-, CPU-Usage-, node/pod- und Container-Metriken können direkten Einblick geben, wo Performance-Engpässe herkommen. Mit Prometheus Node Exporter bekommen Anwender detaillierte Einblicke. Manchmal kommen auch langsame oder mit Paketverlust behaftete Verbindungen ins Spiel, weil eine nicht geplante Route zwischen CI/CD-Server und -Runner verläuft.
Noch tiefer: Pipeline Tracing
Wie im einführenden Artikel "Observability als Denkweise" beschrieben, vertieft Tracing die Fehlersuche, denn neben Metriken und Logs erhalten Anwenderinnen und Anwender damit zusätzliche Observability-Datentypen. Diese erkennen auch vollkommen unvorhersehbare Faktoren (Unknown Unknowns). Ein Beispiel: Die Monatsabrechnung einer Cloud-Infrastruktur wächst stetig, während die Analyse der Ressourcen-Graphen im Monitoring nur eine konstante Auslastung mit einigen Spitzen zeigt, die jedoch auf keinerlei Ursachen zurückschließen lassen. Nachdem das DevOps-Team alle Daten auf einer CI/CD-Observability-Plattform gesammelt hatte, ergab das Metrik-Monitoring Lastspitzen Mittwoch um 11 Uhr.
Die zugehörigen Logs zeigen Applikations-Timeouts bei ausgehenden Requests, und Traces von den CI/CD-Pipelines liefern Aufschluss darüber, dass bestimmte Abhängigkeiten-Downloads in DNS-Resolve-Timeouts laufen. Die daraus resultierenden Wiederholungsversuche wurden überschattet von ungeduldigen Benutzern, die zusätzliche manuelle Jobs anstießen, um das Pipeline-Ergebnis noch vor der Mittagspause dokumentieren zu können. Das Problem löste sich, nachdem stabile Netzwerk-Routen und DNS-Server konfiguriert waren.

Erste Ergebnisse im Tracing liefert die Laufzeit von Abschnitten: Eine Pipeline mit Stages und Jobs lässt sich anhand der Laufzeit aller Komponenten als Zeitstrahl visualisieren. Ähnlich zur Ladezeit einer Webseite, die man mittels Browser-Development-Tools auf potenzielle Probleme untersuchen kann, gibt die Laufzeit von Jobs fundierten Einblick.
Eine einfache Möglichkeit zum Messen der Ausführungszeiten von Scripts ist, sich Start- und Endzeit in Shell-Variablen zu merken und dann die Differenz zu berechnen. Das Beispiel in Listing 3 zeigt einen Job für die Installation von Node.js mit vielen Einzelschritten. Die Variablen START und END speichern die aktuelle Zeit in Sekunden, und der echo-Befehl gibt die Differenz im CI/CD-Log aus. Der Befehl apt update && apt -y install nodejs dauert hier zu lange, weil apt standardmäßig alle Empfehlungen installiert. Der Parameter --no-install-recommends würde die Laufzeit verringern.
Listing 3: Eine Zeitmessung im Skript zeigt Mängel in der Konfiguration
build-nodejs:
stage: build
image: ubuntu:22.04
script:
- export START=`date +%s`
- apt update && apt -y install curl
- export END=`date +%s`
- echo "Duration: $((END-START))"
- export START=`date +%s`
- curl -fsSL https://deb.nodesource.com/setup_current.x | bash -
- export END=`date +%s`
- echo "Duration: $((END-START))"
- export START=`date +%s`
- apt update && apt -y install nodejs
- export END=`date +%s`
- echo "Duration: $((END-START))"
- export START=`date +%s`
- npm install
- export END=`date +%s`
- echo "Duration: $((END-START))"In der Praxis ist dieser Logging-Ansatz jedoch fehleranfällig und verschlechtert die Lesbarkeit der Konfiguration. Die Open-Source-Community und Observability-Anbieter haben unterschiedliche Tools entwickelt, die das Problem besser beherrschen. Clientseitige Tracer erhalten dabei die Informationen, die die CI/CD-Systeme ihnen zur Verfügung stellen. Oftmals fragen sie zusätzlich noch API-Endpunkte der Pipeline ab, um die gesammelten Daten mit mehr Kontext anzureichern.

Die Online-Konferenz Mastering Observability am 11. Juni 2024 zeigt, wie ein ganzheitlicher Observability-Ansatz dabei hilft, Softwaresysteme zu verstehen, zu steuern und zu verbessern. Die von iX und dpunkt.verlag organisierte Online-Konferenz richtet sich an Entwicklerinnen, Entwickler, Ops-Fachleute und DevOps-Teams, die Probleme in CI/CD, Deployment und Operations schneller aufspüren wollen und den Ursachen auf den Grund gehen möchten – mit dem Ziel, Mängel gezielt zu beheben und in Zukunft möglichst zu vermeiden.
Interessierte können sich jetzt für die Mastering Observability anmelden – das Ticket kostet bis 13. Mai 2024 zum Frühbucherpreis 229 Euro, danach dann 279 Euro (alle Preise zzgl. MwSt.). Gruppen ab drei Personen erhalten im Ticketshop darüber hinaus automatisch mindestens 10 Prozent Rabatt.
Wer über den Fortgang der Konferenz Mastering Observability auf dem Laufenden bleiben möchte, kann sich auf der Website für den Newsletter registrieren oder den Veranstaltern auf LinkedIn folgen – der aktuelle Hashtag lautet #masteringobs.