

AMDs KI-Beschleuniger MI300A/X sollen Nvidias H100 deutlich schlagen
AMD nennt konkrete Leistungswerte zum KI-Beschleuniger MI300X und dem HPC-Chip MI300A. Sie sollen schneller und vor allem effizienter als Nvidias H100 sein.

Der KI-Hypetrain läuft weiter unter Volldampf und (nicht nur) AMD will sich seine Chancen auf ein möglichst großes Stück von diesem Kuchen wahren. Für Beschleuniger in Rechenzentren – inklusive Grafikchips und FPGAs – erwartet die Firma nach wie vor einen 150 Milliarden US-Dollar schweren Markt im Jahr 2027. Das bekräftigte AMD am Dienstag auf der "Advancing AI" getauften Informationsveranstaltung im kalifornischen San Jose erneut.
Dazu unterfüttert AMD seine Mitte 2022 angekündigten, Anfang des Jahres erstmals gezeigten und Mitte 2023 erneut präsentierten Instinct MI300-Beschleuniger nun mit weiteren Salamischeiben in Sachen Details und Leistungsdaten. Die MI300 sollen auch aufgrund des bis zu 192 GByte großen Speichers gut gegen Nvidias H100 und zum Teil auch GH200 abschneiden. Vom MI300 gibt es anfangs zwei Versionen, den MI300X für den Standard Open Accelerator Module (OAM) und den MI300A für die CPU-Fassung SH5. AMD liefert beide bereits an Partner aus und sagte auf Nachfrage zu einer reinen CPU-Version, "es gebe eine Chance", dass diese noch kommt.

(Bild: AMD)
Chiplets mit 3D-Stacking

Beide MI300-Varianten fertigt AMD mithilfe von Chiplets, die nun allerdings auch übereinander angebracht werden, also im 3D-Stacking-Verfahren. Zudem kommen auch die 2.5D-Packaging-Verfahren früherer CDNA3-, Ryzen- und Epyc-Chips zum Einsatz. Das Resultat nennt AMD 3.5D-Packaging. Zuunterst sind vier I/O-Dies (IOD) angebracht, die nicht nur die restlichen Chiplets verbinden, sondern mittels Through-Silicon-Vias auch die Versorgung sicherstellen und jeweils 64 MByte Infinity-Cache sowie Speichercontroller für zwei HBM3-Stapelspeicher, für insgesamt also 256 MByte Infinifty Cache und 8 HBM-Stapel, enthalten. Das IOD versorgt jedes per Hybrid-Bonding-Verfahren aufgebrachte Accelerator Complex-Die (XCD) mit bis zu 2,1 TByte/s an Daten, über den gesamten MI300X sind das zusammen 16,8 TByte/s.

(Bild: AMD)
Untereinander kommunizieren die IODs (und damit die aufgebrachten Logikchips) an der Längsseite mit 1,5, an der Stirnseite mit 1,2 TByte/s. Mit diesen Datenraten können sie immerhin den Speicherzugriff auf entfernte Controller fast komplett durchleiten, wenn auch mit zum Teil erhöhter Latenz (bei zwei IOD-Sprüngen, da es keine Querverbindung gibt). Als wäre das nicht genug, stellen die IODs auch noch 8 × 16 Lanes des Infinity Fabrics bereit, die Hälfte, also 4 × 16 lässt sich auch zur Anbindung von PCI-Express-5.0-Geräten nutzen. Jede dieser Linkgruppen kann 64 GByte/s pro Richtung übertragen. Vier MI300A lassen sich so mit 384 GByte/s verbinden, acht MI300X kommen auf 896 GByte/s, wenn man alle sieben Außenverbindungen, die nach der x16-PCIe5-Anbindung zur CPU noch übrig bleiben, addiert. Die rund 13 × 29 Millimeter großen Chips werden im günstigen und bewährten N6-Prozess bei TSMC hergestellt.

(Bild: AMD)
Die Logikchips werden in modernerer 5-Nanometer-Technik bei TSMC gefertigt und kommen, anders als bei AMDs 3D-V-Cache-Technik, oben auf die IODs drauf, sodass sich die Abwärme besser fortleiten lässt. Für die CPU-Kerne mit acht Kernen, die sich jeweils 32 MByte L3-Cache teilen, nutzt AMD die gleichen CPU-Complex-Dies (CCDs) wie beim Epyc 9004. Die XCDs enthalten jeweils 40 CDNA3-Compute-Units, von denen je zwei allerdings aus wirtschaftlichen Gründen abgeschaltet sind. Ein MI300X mit acht XCDs hat folglich 304 (aktive) Compute Units mit 19.456 Rechenkernchen und 1216 Spezialeinheiten für Matrizenmultipllikation.
Bis zu 750 Watt und 32 Prozent schneller als Nvidia H100
AMD gibt die Thermal Design Power (TDP) des MI300X mit bis zu 750 Watt an und zeigte Leistungswerte für den MI300A mit bis zu 760 Watt. Da die Beschleuniger allerdings erheblich schneller als die der vorigen Generation arbeiten, ergibt sich daraus netto ein Effizienzgewinn, betrachtet man die Performance pro Watt. Bei dicht besetzten Matrizen mit INT8-Genauigkeit etwa, wie sie beim KI-Inferencing, also der Anwendung bereits trainierter Modelle, oft genutzt wird, liefert MI300X auf dem Papier mit rund 2,6 Billiarden Operationen pro Sekunde (PetaOPS) rund 6,8x soviel Durchsatz wie der Vorgänger MI250X und immer noch 32 Prozent mehr als Nvidias aktueller H100 SXM. Die dafür nötige, maximale Taktrate beträgt 2100 MHz, der Vorgänger Instinct MI250X musste noch mit 1700 MHz auskommen.
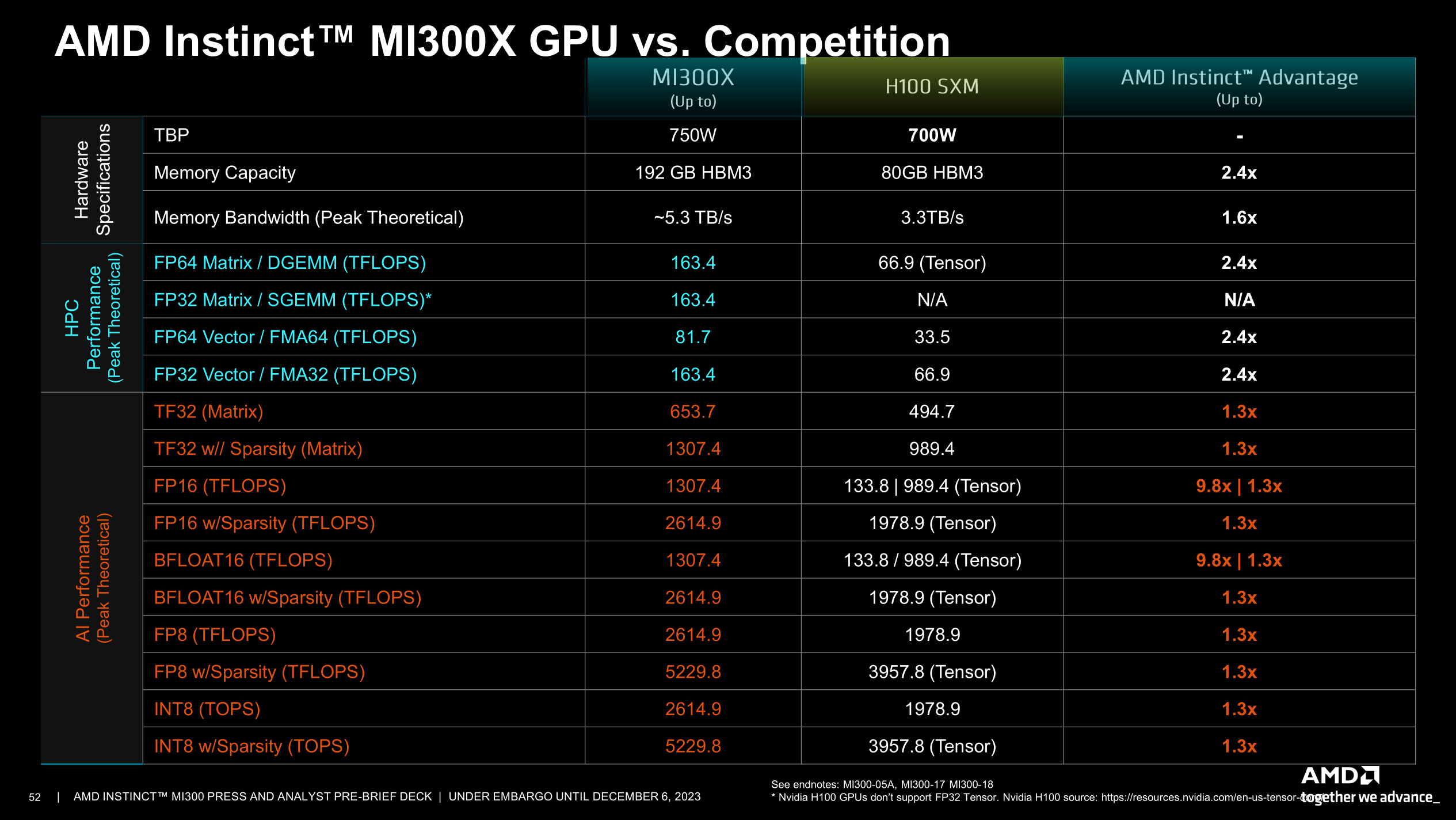
(Bild: AMD)
Der MI300X ist dabei als reiner Beschleuniger innerhalb eines klassischen Rack-Servers konzipiert und soll "Leadership AI Performance", also die höchste Leistung für KI-Anwendungen liefern. Der Beschleuniger benötigt fürs Booten, den Betrieb des OS und zur Versorgung die Hilfe einer CPU wie zum Beispiel AMDs Epyc oder Intels Xeon. Der MI300A tauscht ein Viertel der Beschleuniger-Rechenkerne gegen 24 CPU-Cores auf Basis von Zen 4 des Epyc 9004 und funktioniert auch auf sich allein gestellt. Mehr noch: Da CPU- und Beschleunigerkerne gemeinsam auf den lokalen Speicher zugreifen ("Shared Memory"), entfallen viele zeitraubende Kopieraktionen und etliche Algorithmen können deutlich effizienter arbeiten und schneller laufen.
AMD sieht den MI300A dagegen hauptsächlich im Bereich des High-Performance-Computing und stattet unter anderem den kommenden 2-Exaflops-Supercomputer El Capitan damit aus, wie AMDs Forrest Norrod noch einmal bestätigte.
Schneller als Nvidias H100 dank 8 x HBM3
Der MI300X trumpft mit fetten 153 Milliarden Transistoren und 192 GByte HBM3-Speicher auf; den MI300A mit 146 Mrd. Transistoren beschränkt AMD auf 128 GByte – wegen des unterschiedlichen Anwendungsprofils, sagte AMD. Dennoch hat jeder der beiden acht HBM3-Stapel, nur eben mit Kapazitäten von 24 beziehungsweise 16 GByte. Ein HBM3-Stapel liefert 665 GByte pro Sekunde und das Gesamtpaket damit rekordverdächtige 5,3 TByte/s.

(Bild: AMD)
Die Kombination aus Speichergröße und -transferrate verhilft unter anderem einigen KI-Anwendungen zu mehr Leistung, sodass AMDs sich gegen Nvidias etablierte H100-Beschleuniger gut aufgestellt sieht. Man vergleicht die MI300 allerdings nur gegen die H100-Variante mit 80 GByte, solche mit 96 bis 141 GByte hat Nvidia bereits angekündigt.
Bei Inferencing von KI-Anwendungen sieht man sich, etwa bei Flash Attention 2 oder Llama2-70B, mit 10 bis 20 Prozent vor Nvidias H100. In einem Server mit acht Beschleunigern sind laut AMD bei noch größeren Large-Language-Modellen wie Bloom mit 176 Mrd. Parametern die Durchsatzwerte (Token/s) um bis zu 60 Prozent besser als bei Nvidias H100 HGX. Beim KI-Training (Databricks MPT, 30 Mrd. Parameter) hingegen sieht sich AMD selbst nur auf Augenhöhe mit Nvidias Angebot. Durch den mehr als doppelt so großen Speicher könnten allerdings auch zwei Modelle zugleich trainiert werden (was dann aber durch die Rechenleistung beeinträchtigt würde) oder doppelt so große, etwa mit 70 Mrd. Parametern statt nur mit 30.
Die MI300A soll speziell bei der Effizienz und durch die Vorteile des gemeinsamen Speicherzugriffs von CPU und GPU-Kernen auftrumpfen. Gegenüber Nvidias H100, das konventionell mit seinen CPUs kommuniziert, sieht sich AMD um Faktor 4 im Vorteil, wenn man den HPC-Motorbike-Test der CFD-Simulation OpenFOAM heranzieht. Gegenüber Nvidias kommender GH200, deren CPU- und GPU-Teile ebenfalls gemeinsam auf den Speicher zugreifen dürfen, zieht AMD dann aber einen anderen Vergleich: Beim theoretischen Rechendurchsatz will man die doppelte Leistung pro Watt erreichen und zieht dabei Nvidias TDP-Angabe von 1000 Watt für den Grace-Hopper-Superchip als Vergleich heran.
Spannend: Von Intels DataCenter GPU Max alias Ponte Vecchio war mit keiner Silbe die Rede.

(Bild: AMD)
RocM 6 noch im Dezember 2023
Ohne passende Software nützt die beste Hardware nichts. Diese Binsenweisheit musste AMD am eigenen Leib erfahren, nachdem Nvidia den KI-Markt bereits sehr früh für sich entdeckte und mit etlichen Bibliotheken und Framework-Unterstützung für die hauseigene CUDA-Plattform vereinnahmte.
Mit MI300 will man nun den Fokus auf offene Standards und die Open-Source-Community ausweiten. Dafür arbeitet man nun proaktiver mit AI-Softwareanbietern wie HuggingFace oder dem Framework PyTorch zusammen.
Im Laufe des Dezembers will AMD dazu die Programmierumgebung-Schrägstrich-Software-Plattform ROCm in Version 6 veröffentlichen. Diese soll MI300 direkt unterstützen und zumindest später auch viele der modernen Radeon-GPUs, die inzwischen ROCm-Support haben, wie die Radeon RX 7900 XTX.
In einem etwas schrägen Vergleich gibt man einen Performance-Vorteil von Faktor 8 für ein System mit vier MI300X mit ROCm 6 gegen ROCm 5 auf vier MI250 (ohne X!) an. Der Wert bezieht sich auf die Inferencing-Latenz eines Llama-2-Modells mit 70 Milliarden Parametern. Schräg ist der Vergleich deshalb, weil außer neuer Software-Versionen auch höchst unterschiedliche Hardware zum Einsatz kommt. So haben die MI300X nicht nur 192 statt 128 GByte Speicher, sondern dürfen jeweils auch 190 Watt mehr schlucken (750 statt 550 Watt).
Auch OpenAI, die Firma hinter ChatGPT, hat man mit ins Boot holen können, sodass deren kommende 3.0-Distribution der pythonähnlichen Programmierumgebdung Triton AMDs Mi300 wie auch andere GPUs direkt ab Werk unterstützen wird.
Hinweis: AMD hat Reise- und Hotelkosten für den Autor übernommen.


(csp)
